摘要: 在蚂蚁金服&阿里云在线金融技术峰会上,周俊详细介绍了阿里巴巴大规模机器学习框架——参数服务器的设计理念以及优化方法,并结合支付宝、阿里妈
妈直通车搜索广告等具体场景详解了参数服务器在蚂蚁金服和阿里内的应用;分享最后,他对大规模机器学习的未来发展做了展望。
本 文根据蚂蚁金服的资深技术专家周俊在蚂蚁金服&阿里云在线金融技术峰会上《大规模机器学习在蚂蚁+阿里的应用》的分享整理而成。在分享中,周俊详 细介绍了阿里巴巴大规模机器学习框架——参数服务器的设计理念以及优化方法,并结合支付宝、阿里妈妈直通车搜索广告等具体场景详解了参数服务器在蚂蚁金服 和阿里内的应用;分享最后,他对大规模机器学习的未来发展做了展望。
直播视频:点击此处观看
幻灯片下载:点击进入
以下为整理内容。
---------------------------------------------------------------------------------------------------------------------------------
设计理念

图一 大数据时代
当 今我们正处于一个大数据时代,Google每天产生30亿查询、300亿Served广告、30万亿indexed网页;FaceBook目前全球超过 14亿用户,每天分享43亿内容;推特每天产生4.3万亿Tweets;Apple Store每天App下载量达到1亿左右。国内的互联网公司,阿里巴巴一年产生86亿包裹,平均每天2356万个;蚂蚁金服/支付宝在2015年双十一当 天共产生7.1亿笔支付。
这么多数据如何才能有价值地将其利用起来呢?
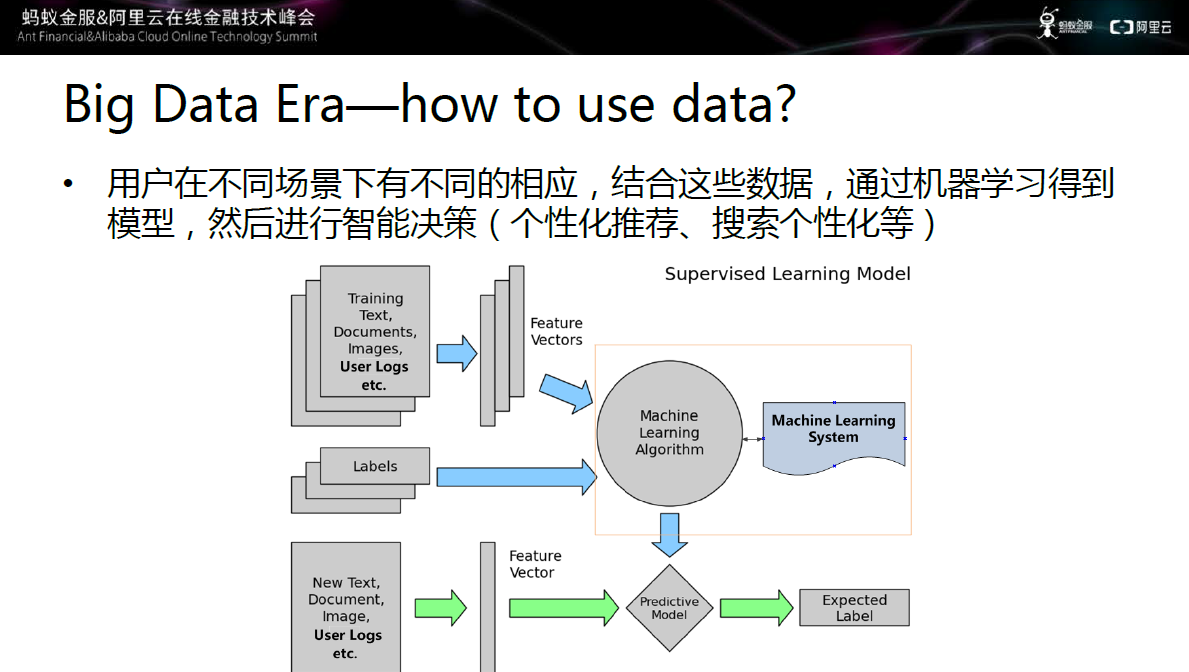
图二 如何利用大数据
用 户在不同场景下有不同的响应,结合这些数据通过机器学习得到模型,然后进行智能决策,如个性化推荐、搜索个性化等。上图中显示的监督学习的案例,监督学习 通过搜集大量用户的日志、用户行为,然后抽取成特征,然后将特征送入机器学习系统中,系统通过一定的方式得到相应的模型。一个用户到来之后,对用户特征进 行提取,将用户特征送入模型中,得到预测结果。例如记录用户的点击。购买、收藏等行为,经过模型的预测,根据用户之前的偏好,进行个性化推荐。
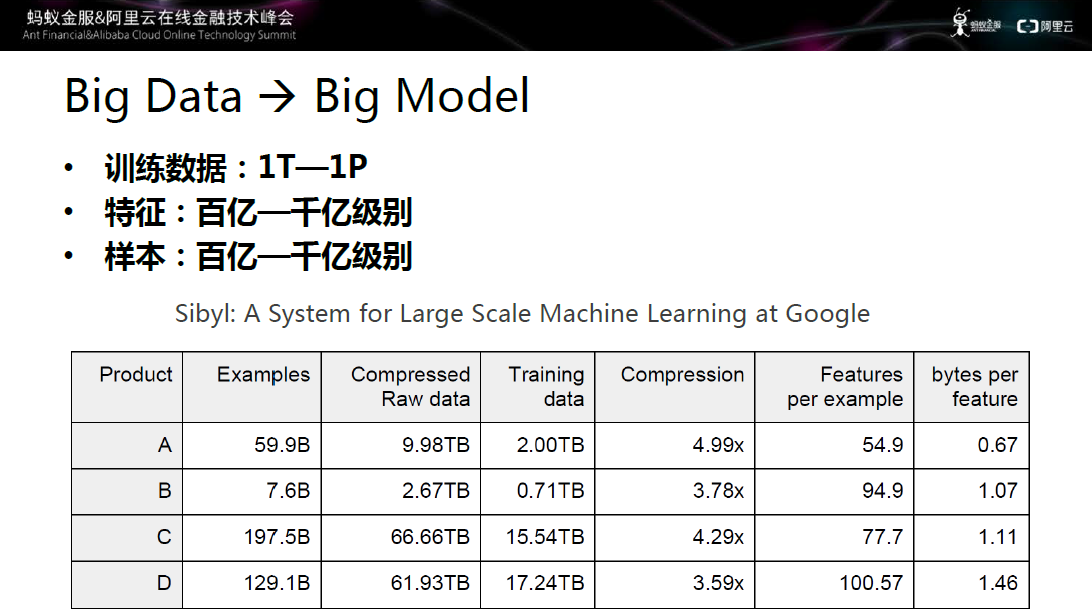
图三 大数据带来的挑战
大数据给机器学习带来机遇的同时也带来了相应的挑战。第一个挑战是模型会非常大,谷歌的大型机器学习系统Sibyl,五年前的训练数据在1T到1P左右,特征级别达到百亿到千亿级别;样本同样是百亿到千亿级别。
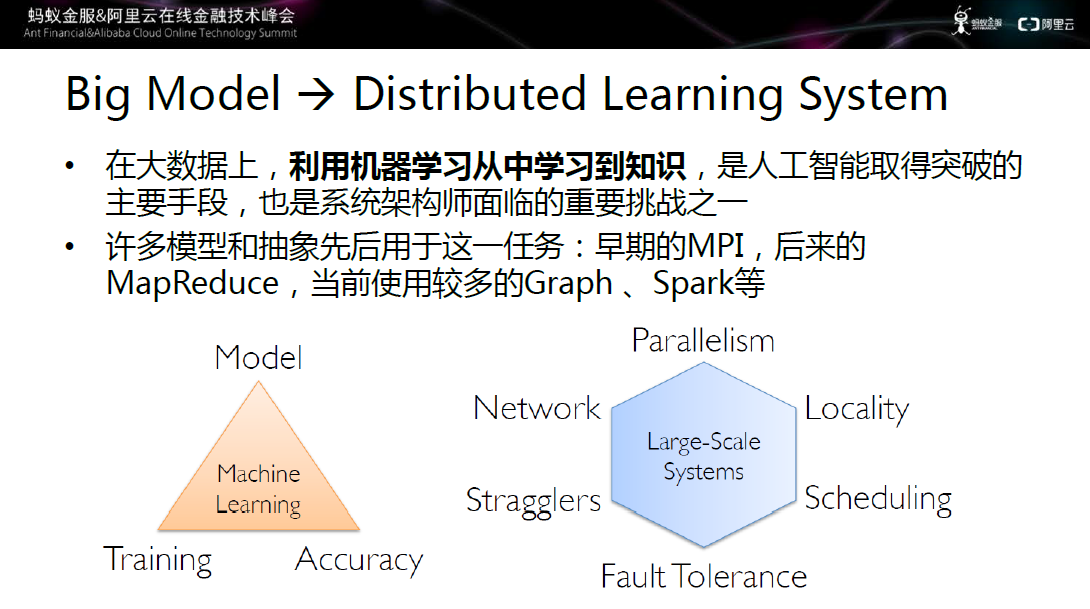
图四 大数据与大规模模型结合
如此大的数据和如此大的模型如何进行结合呢?思路是采用分布式学习系统,结合算法和系统两方面入手。
正如上文所提到的,在大数据上,利用机器学习从中学习到知识,是人工智能取得突破的主要手段,也是系统架构师面临的重要挑战之一。很多的模型和抽象先后用于解决这一任务,从最早期的MPI,到后来的MapReduce,再到当前使用较多的Graph、Spark等。
分布学习系统包括两大模块:模型和分布式系统。其中模型需要解决训练和正确率的问题,分布式系统需要考虑并行、网络、慢机、故障处理、调度。
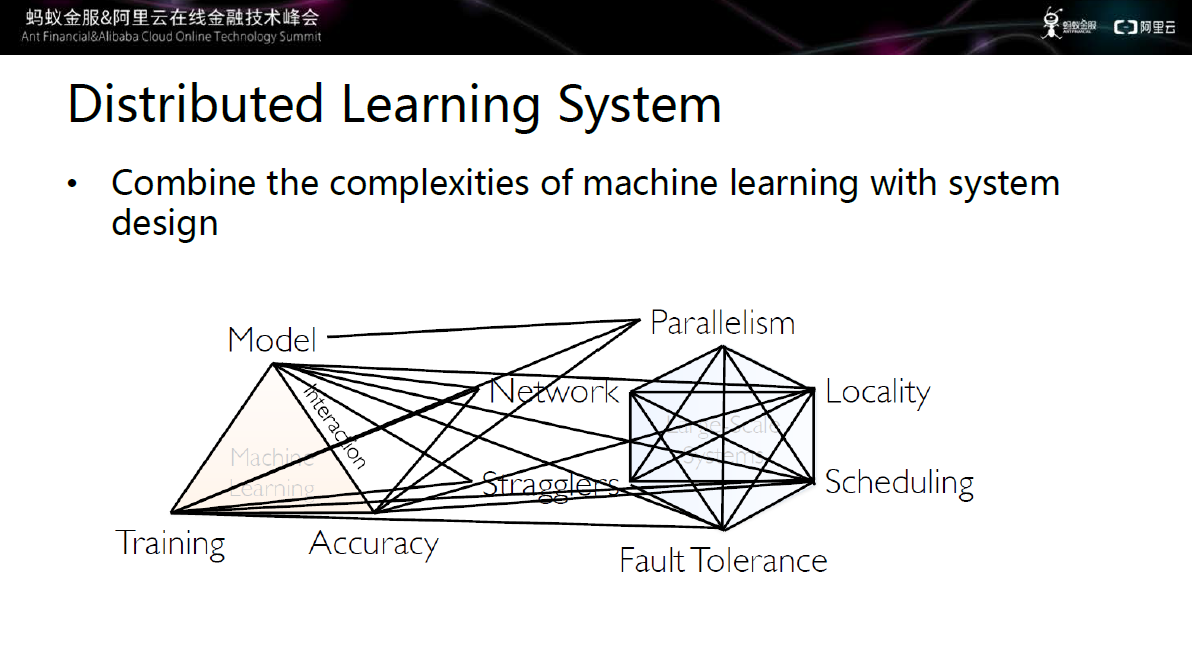
图五 分布式学习系统
如上图所示,分布式学习系统将两者的复杂度结合起来。每一个维度和算法都有融合、交叠。在网络方面,需要考虑网络的通信效率,因为模型非常大,如果直接预发会造成网络的巨大负担,如果有些流量不发,又会影响训练和模型的正确率。
慢 机方面,在数千台机器中,肯定会存在机器处理速度的差异,如果采用完全同步的方法,迭代的速度是取决于最慢的机器,这就造成了资源的巨大浪费。第三故障处 理,数千台机器中一定会出现机器挂掉的现象,机器挂掉之后如何让训练继续进行,获得正确的训练模型这也是一个非常大的挑战。

图六 工业界现有的系统的不足
首先看一下现有工业界系统的缺点:
-
MapReduce:迭代式计算低效,节点之间通信效率不高;
-
MPI:无法支撑大数据,任意节点挂掉,任务就失败;
-
Graph:用图来做抽象,类似深度学习无法高效求解,只能同步,不支持异步;
-
Spark:通用框架,高维度和稀疏数据支持不够;
综合考虑模型训练正确率、故障处理、慢机等因素,性价比高的选择是参数服务器(Parameter Sever)。
大规模机器学习框架-参数服务器

图七 大规模学习框架——参数服务器
参数服务器是机器学习的核心竞争力和技术壁垒之一,之所以这么说是因为:首先,它需要使用大数据(1T-1P)快速训练、快速迭代优化;同时需要考虑failover、通信/计算效率、收敛速度等多个特性。
在之前的分析中,阿里巴巴的ODPS中的MPI为例,统计了MPI中的Job的成功率(上图所示),当Work数超过1000时,成功率低于30%,从而导致稳定性很差,浪费大量的资源和费用。由于存在稳定性和成功率等问题,我们自己设计了一套参数服务器框架。
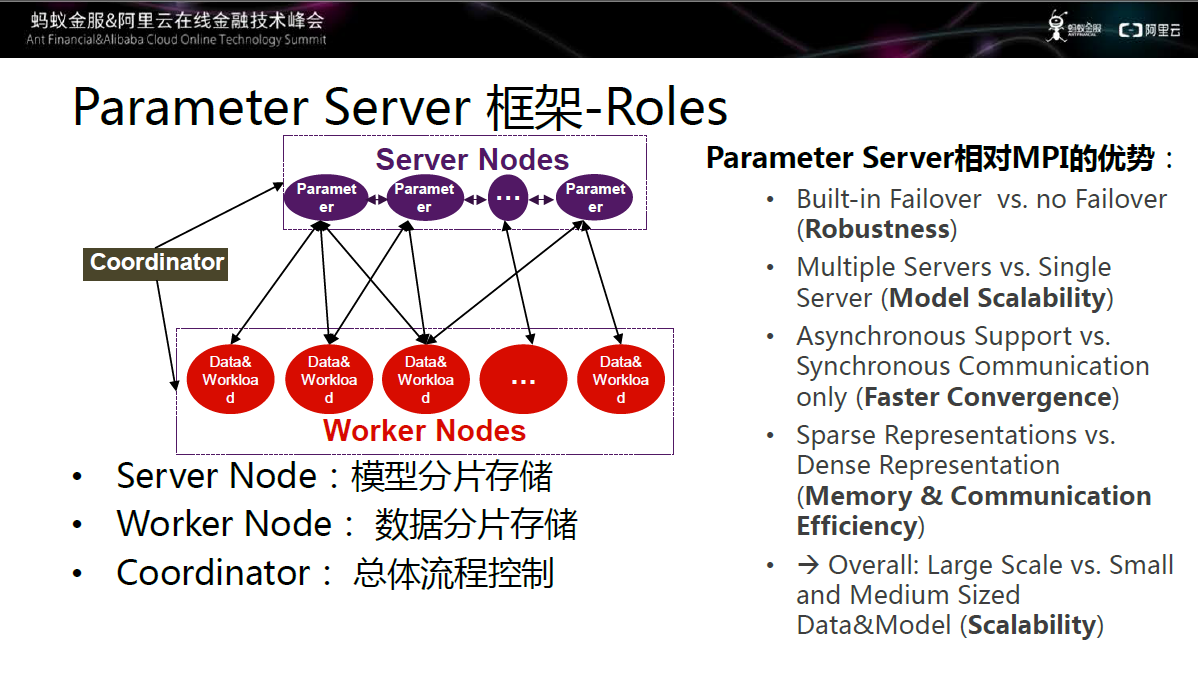
图八 参数服务器框架图
框架的大致结构如上图所示,包括三大模块:Server Node、Worker Node、Coordinator,分别用于模型分片存储、数据分片存储和总体流程控制。该结构相对于MPI的优势在于:
-
内置Failover机制,稳健性大大提升;
-
架构中有多个Server,模型的可扩展性非常强;
-
完美支持同步和异步,可以达到更快的收敛速度,同时不影响模型的精度;
-
同时在稀疏性的上支持,让worker和server节点在通信效率上大幅度提升。
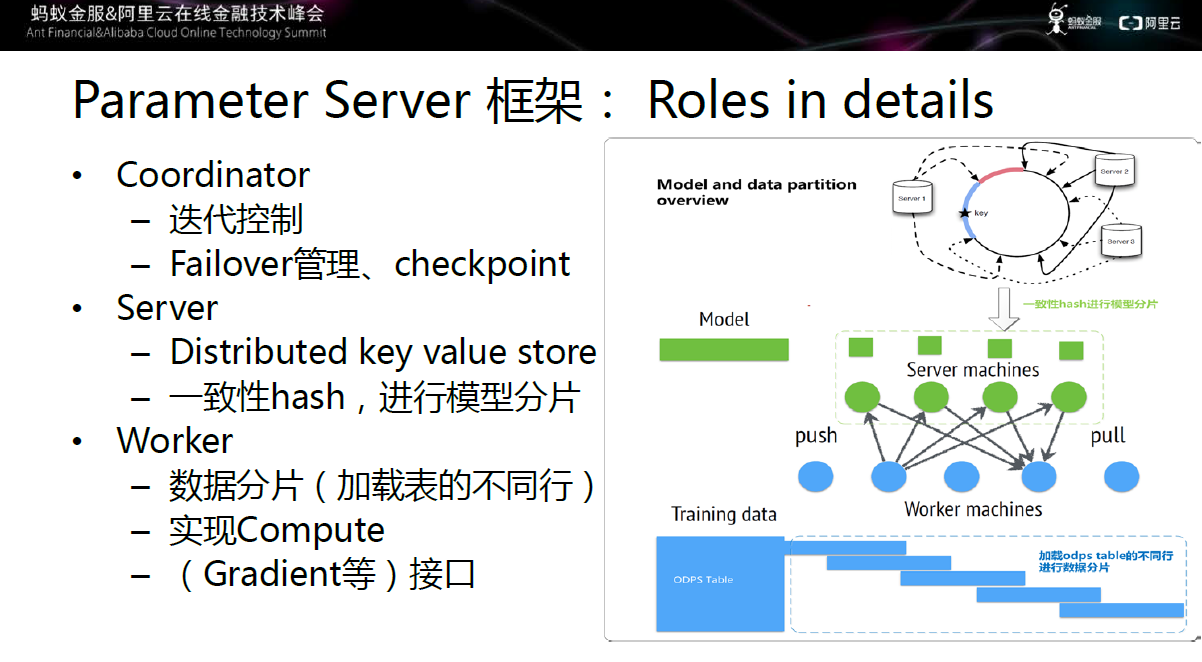
图九 参数服务器具体框架
具 体来讲,Coordinator主要进行迭代控制,同时完成Failover管理,当Worker或Server挂掉时,由Coordinator进行处 理;当Worker、Server和整个Job都失败的情况下,通过Checkpoint机制,在下一次启动时从上一次保存的中间结果继续前进。
Sever本质上是分布式Key-value存储系统,它将一个非常大的模型,通过一致性Hash切成多片,在多个Server上分担压力,进行模型分片。
Worker是将数据源的不同行加载到不同的Worker上,实现数据分片,同时通过计算接口完成梯度计算。
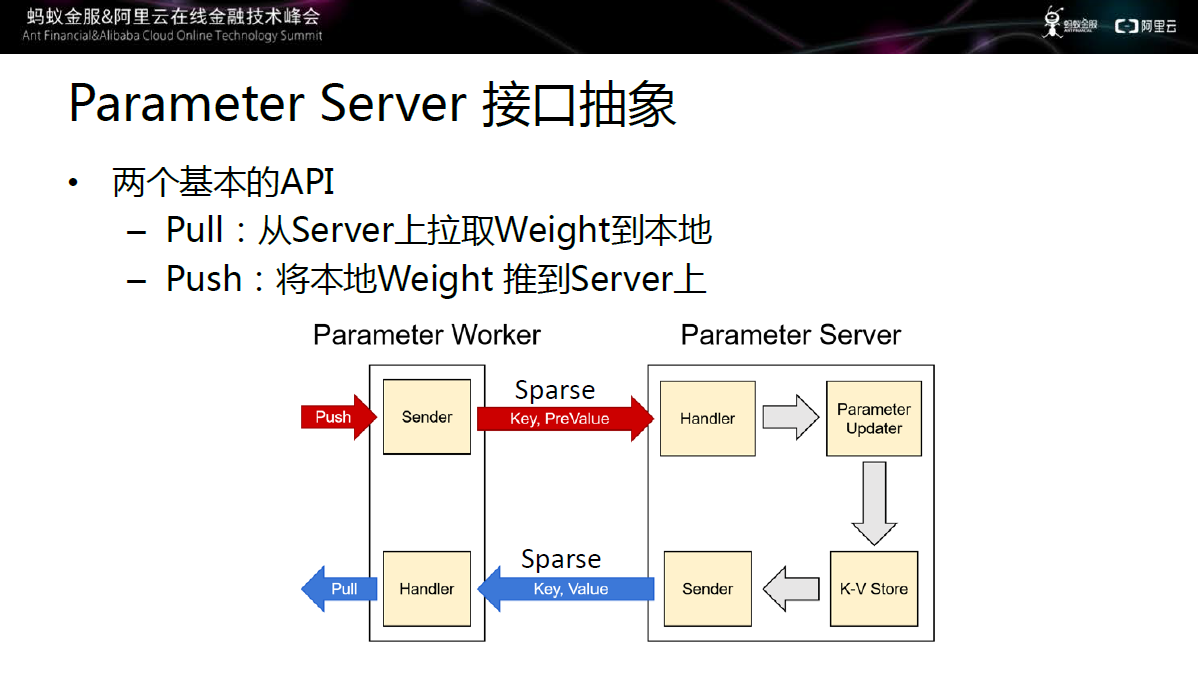
图十 参数服务器抽象接口
Worker 和server通过Pull和Push两个接口进行通信,完成模型的迭代更新。Push主要是将worker上的Weight推到server上,从而节 省大量的流量,提高网络利用率;server更新之后,worker通过Pull动作从server上拉去Weight到本地。
Sever更新策略
Server有三种更新策略。
完全同步更新策略
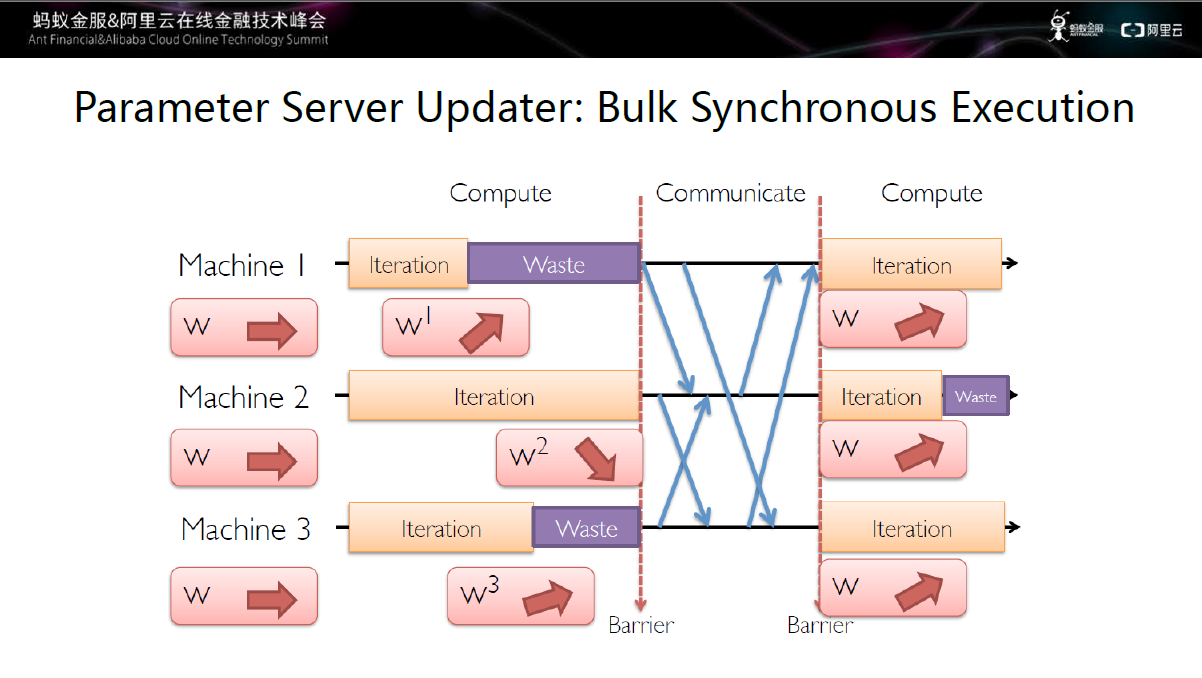
图十一 完全同步更新策略
第 一种完全同步更新,图中所示的机器1和机器3虽然很早就完成了Iteration,但由于机器2是慢机,所以机器1、机器2、机器3需要等待最慢的机器完 成iteration,才可以与server进行通信,这中间存在大量的资源浪费,但也有一定的优点:收敛性很好,多次运行后模型差别不大,同时还便于调 试。
完全异步更新策略

图十二 完全异步更新策略
第二种更新机制完全与第一种更新机制相反:完全异步更新。完全异步是说机器1、机器2、机器3随到随走,三者之间互相不可见,唯一的交互点是Parameter Server。这种更新策略的效率非常高,各机器之间没有任何等待。同时也会带来一些问题,收敛很困难。
有界异步更新策略
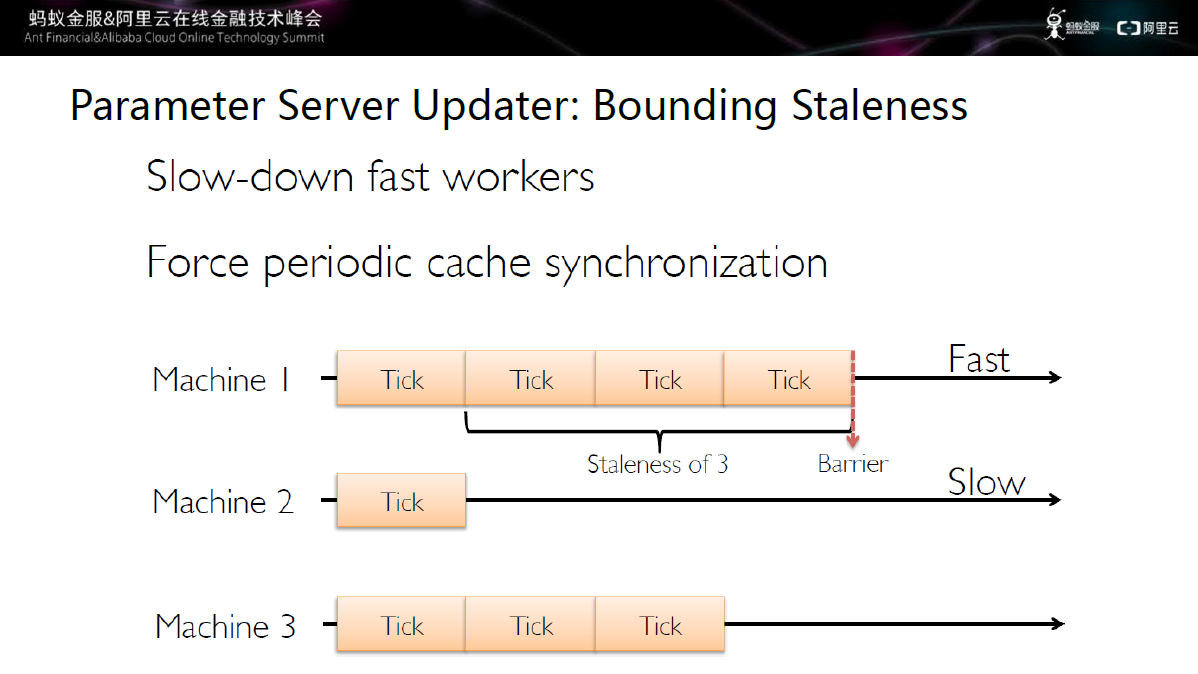
图十三 有界异步更新策略
第三种更新策略介于完全同步和完全异步之间,称之为有界异步。有界异步可以从机器1和机器2上看出,最快的机器不能比最慢的机器快太多,两者之间有一定的界限。通过这种机制提高模型的稳定性。
参数服务器在算法上的优化

图十四 参数服务器与逻辑回归算法结合
逻 辑回归是一种线性回归模型,在分类上应用广泛,通过logit函数将线性回归的值限制在[0,1]范围内,增强了模型的鲁棒性。在工业界应用较多的是稀疏 逻辑回归,通过L1正则化构造稀疏模型,具有简单、实用、可扩展、特征操作性强等特点,适合大规模问题,同时应用场景非常丰富(如点击率估算),是应用非 常广泛的机器学习模型。
如何结合Parameter Server对逻辑回归进行改进呢?
目前,我们实现了超大规模的CTR预估算法,结合Server的更新动作,实现同步/异步的控制。在算法优化方面:
-
应用Proximal算法,进行二阶、异步Filter,提高了效率;
-
开发增量学习,提升模型利用更长历史窗口数据的能力。
全链路优化方面:
-
稀疏化、特征序列化加速、慢机处理、次要特征过滤(screen rule)等。
通过上述机制,最终实现提速超500%,支持千亿级别样本跟特征的效果。

图十六 逻辑回归与在线学习结合
在线学习是工业界常用的另一类算法。在线学习是指每来一个(批)训练样本,就用该样本的梯度对模型迭代一次,时效性较好。
那如何通过Parameter Server对在线学习进行改进呢?
目 前,我们实现了超大规模在线机器学习算法(异步FTRL)。通过有界异步ASGD提高效率,同时模型的收敛性有较强的保证;同时基于mini batch的稀疏通信,在百亿特征下,每个mini batch通信为毫秒级别;此外,在模型中加入类似Trust region的方式,提高模型稳定性。
最终达到100亿/100亿样本几十分钟内就可以收敛的效果。

图十七 其他扩展算法
除了在线和离线之外,还有一些大规模的算法扩展:
-
深度学习,通过在参数服务器上支持深度学习,形成了通用的深度学习框架,扩展性很强,例如,通过从大量click log中学习,提高搜索相关性的DSSM模型加DNN语义模型。
-
其他常用算法,包括LTR的GBDTLambdaMART、GBRank和NLP的LDA、Word2Vec等等。
-
提供了通用SDK,用于降低门槛,便于开发各类算法。
典型应用场景
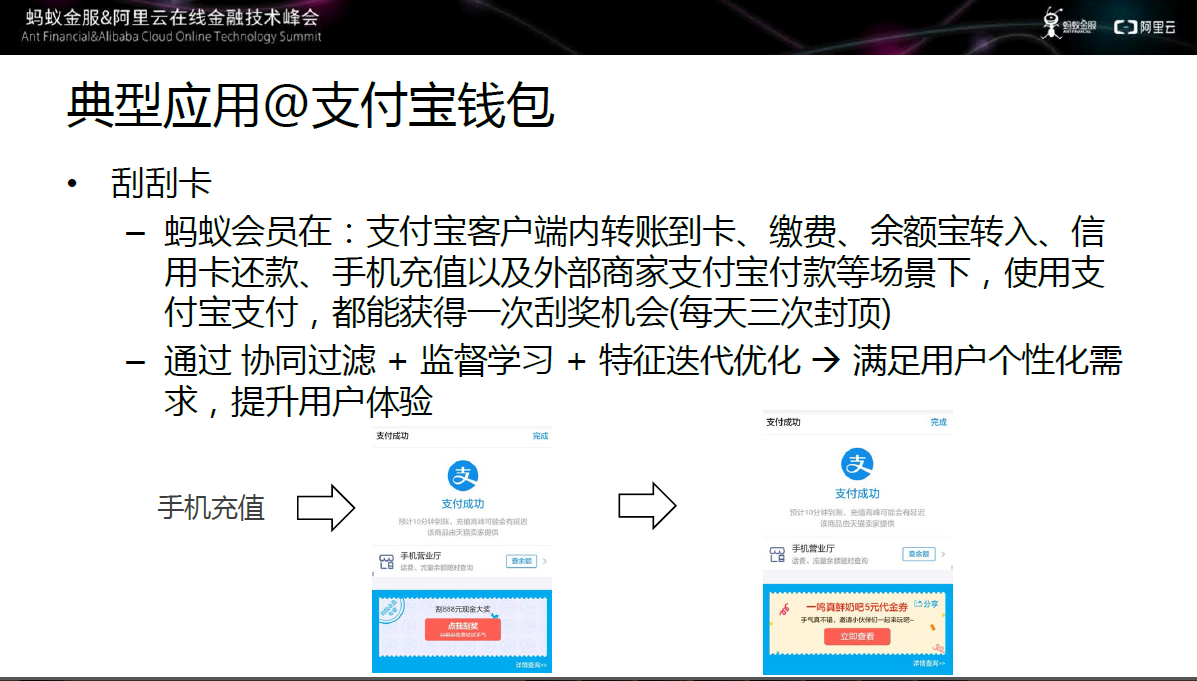
图十八 典型应用一:支付宝钱包
第一个应用场景是支付宝钱包内的刮刮卡业务,蚂蚁会员在支付宝客户端内转账到卡、缴费、余额宝转入、信用卡还款等场景下,使用支付宝支付,都能获得一次刮奖机会。
这其中的实现过程是基于大规模学习平台,通过协同过滤、监督学习、特征迭代优化,来满足用户个性化需求,提升用户体验。
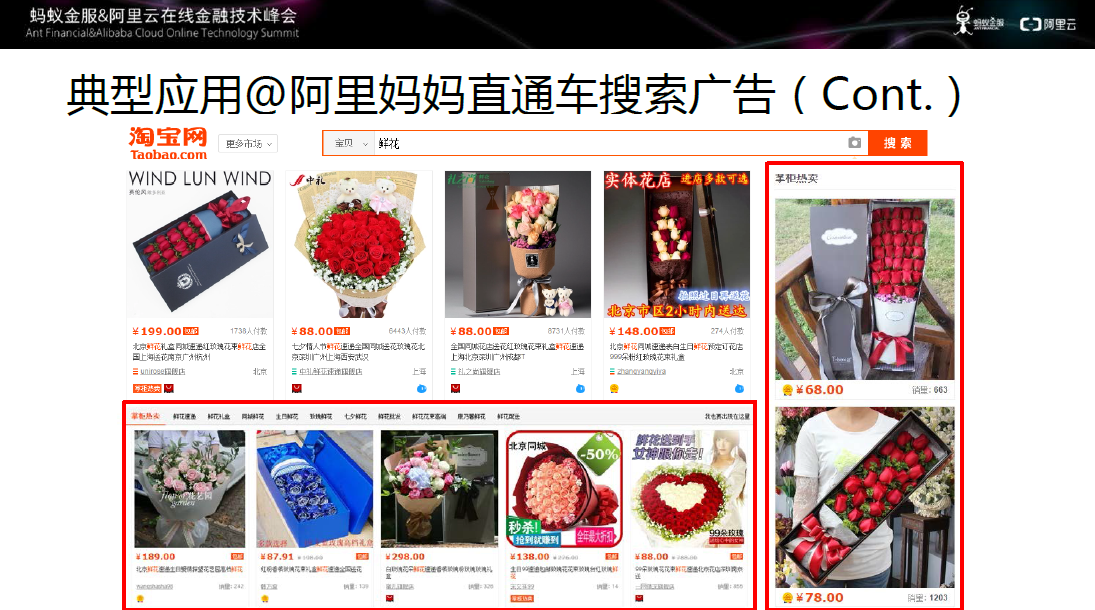
图十九 典型应用二:阿里妈妈直通车搜索广告
在阿里妈妈的应用主要是阿里妈妈直通车搜索广告。计算广告学的核心问题就是在给定的环境下,用户与广告的最佳匹配。它的传统实现方法是通过机器学习和历史数据,进行精准的CTR预估。
结合上图来看,当搜索鲜花时,界面右侧和下侧会显示掌柜热卖的广告,通过采集大量的用户特征、广告特征和场景特征等交叉特征,通过加大特征和样本规模,同时算法和系统协同提升,基于大规模机器学习平台,提升CTR。
未来展望
不论是人工智能还是其他前沿技术,都离不开高质量的数据和强大的计算平台以及高效的算法平台,需要三者协同提升。未来的发展方向主要集中在以下三个方面:
1.支持更多的通用模式,如Graph及其升级版。
2.正确率和效率的折中,是否可以进行采样丢弃部分数据?是否可以通过更好的异步算法充分利用数据?是否可以简化算法本身,更好的适配参数服务器框架?
3.是否需要更加通用化的DataFlow,支持多种软硬件平台,降低大规模机器学习的门槛。
个人资料
推荐圈子

上一篇:
阿里巴巴2016校招笔试题(含答案)
下一篇:架构师必看 京东咚咚架构演进
猜你感兴趣的圈子:
标签: 蚂蚁、异步、server、大规模、worker、面试题
